
模型开源|支持东方40语种+中国22方言的新SOTA语音大模型Dolphin开源啦!
发布时间:2025/04/02
返回列表
在当今数字化时代,语音识别技术已成为人机交互的关键桥梁,广泛应用于智能客服、语音助手、会议转录等众多领域。然而,对于东方语言的识别如越南语、缅甸语等,现有模型往往表现不佳,难以满足用户的需求。为解决这一难题,海天瑞声携手清华大学电子工程系语音与音频技术实验室,共同推出了Dolphin —— 一款专为东方语言设计的语音大模型。


一、核心亮点
- 支持东方40个语种的语音识别,中文语种支持22方言(含普通话);
- 训练数据总时长21.2万小时:其中海天瑞声高质量专有数据13.8万小时,开源数据7.4万小时;
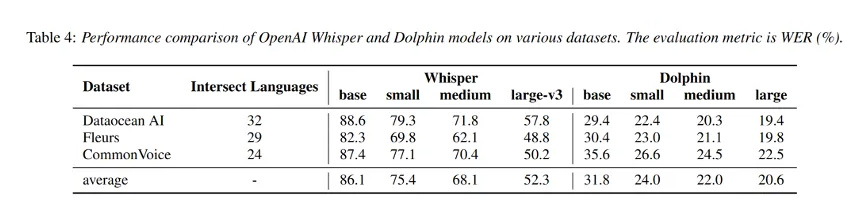
- 在3个测试集(海天瑞声、Fleurs、CommonVoice)下,与Whisper同等尺寸模型相比:
- 版本平均WER降低63.1%;
- small版本平均WER降低68.2%;
- medium版本平均WER降低67.7%;
- large版本平均WER降低60.6%
- 与small版本模型与推理代码全面开源;Dolphin 开源的small版本与Whisper large v3相比,平均WER降低54.1%。
- 论文题目:Dolphin: A Large-Scale Automatic Speech Recognition Model for Eastern Languages
- 论文链接:https://arxiv.org/abs/2503.20212
- Github:https://github.com/DataoceanAI/Dolphin
- Huggingface:https://huggingface.co/DataoceanAI
- Modelscope:https://www.modelscope.cn/organization/DataoceanAI
- OpenI启智社区:https://openi.pcl.ac.cn/DataoceanAI/Dolphin
- 支持的语种:https://github.com/DataoceanAI/Dolphin/blob/main/languages.md
二、创新技术架构
- 模型结构
Dolphin网络结构基于CTC-Attention架构,E-Branchformer编码器和Transformer解码器,并引入了4倍下采样层,以实现高效的大规模多语言语音识别模型的训练。CTC-Attention架构结合了CTC的序列建模能力和注意力机制的上下文捕捉能力,能够有效提升模型的识别准确性和效率。E-Branchformer编码器采用并行分支结构,能够更有效地捕捉输入语音信号的局部和全局依赖关系,为模型提供了更丰富的特征表示。解码器部分则采用了在序列到序列任务中表现出色的Transformer,能够生成高质量的文本输出。为了进一步提高训练效率和性能,我们在模型中引入了4倍下采样层。这一层可以减少输入特征的序列长度,从而加速计算过程,同时保留关键的语音信息,确保模型的识别效果不受影响。
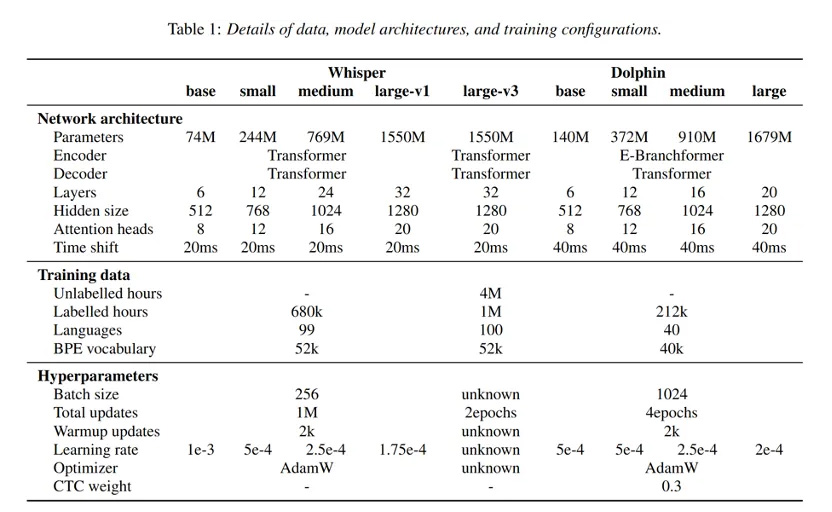
- 多任务格式
Dolphin 借鉴了 Whisper 和 OWSM 的创新设计方法,但专注于ASR 进行了若干关键修改。Dolphin 不支持翻译任务,并且去掉了previous text及其相关标记的使用,这简化了输入格式并减少了潜在的复杂性。
Dolphin引入了两级语种标签系统,以便更好地处理语言和地区的多样性。第一个标签指定语种(例如、),第二个标签指定地区(例如、)。这种分层方法使模型能够捕捉同一种语言内不同方言和口音之间的差异,以及同一地区内不同语言之间的相似性,从而提高了模型区分密切相关的方言的能力,并通过在语言和地区之间建立联系增强了其泛化能力。
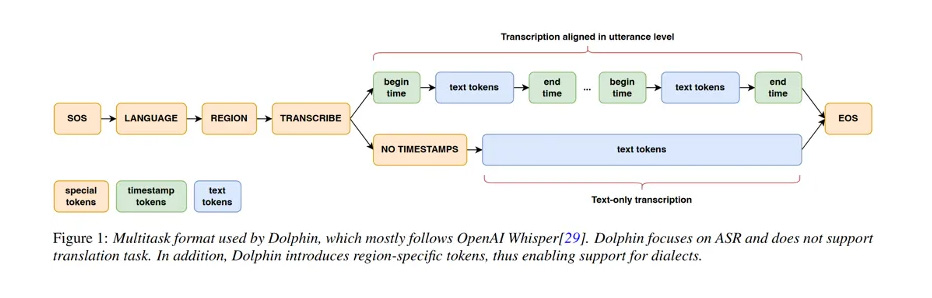
三、强大的数据基础
Dolphin的训练数据集整合了海天瑞声的专有数据和多个开源数据集,总时长超过20万小时,涵盖40个东方语种。其中,海天瑞声数据集包含137,712小时的音频,覆盖38个东方语种。这些高质量、多样化的数据为模型的训练提供了坚实的基础,使其能够更好地适应不同语言和方言的语音特征。
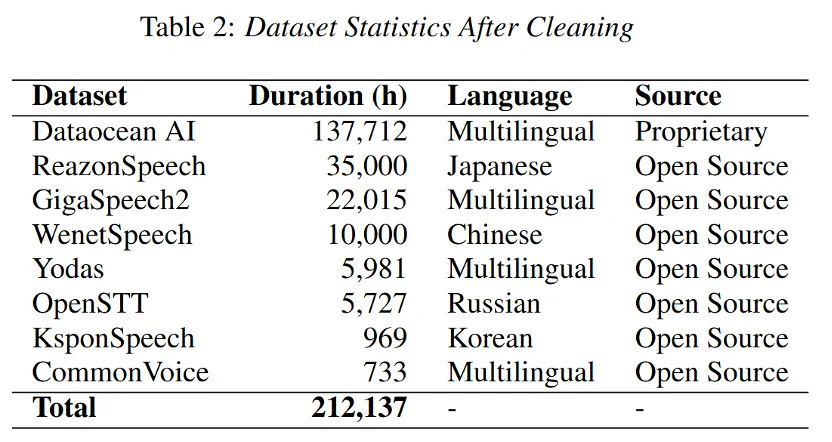
四、卓越性能表现
通过精心设计的架构和大规模的训练数据,Dolphin在多种语言上的词错误率(WER)显著低于现有开源模型。例如,在海天瑞声数据集上,Dolphin 模型的平均WER为31.5%,small模型为24.5%,medium模型为22.2%;在CommonVoice数据集上,Dolphin 模型的平均WER为37.2%,small模型为27.4%,medium模型为25.0%。即使与Whisper large-v3模型相比,Dolphin在模型规模更小的情况下,性能也更为出色。以中文为例,Dolphin中模型的WER仅为9.2%,而Whisper large-v3模型为27.9%。
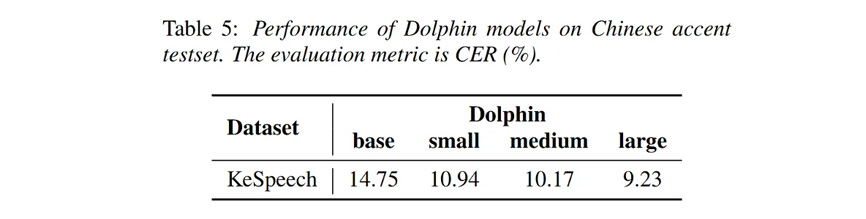
在KeSpeech (包含一个普通话子集和八个中国方言子集)测试集上,Dolphin模型表现出了卓越的效果:
五、开源与社区贡献
为促进语音识别技术的进一步发展,Dolphin的训练模型和推理源代码已公开发布。这一举措不仅为研究人员提供了宝贵的研究基础,也为开源社区注入了新的活力,鼓励更多创新与合作。通过共享技术成果,我们希望能够吸引更多的开发者和研究机构参与到东方语言语音识别的研究中来,共同推动技术的进步。
六、未来展望
Dolphin的开源只是起点。未来,海天瑞声与清华大学电子工程系语音与音频技术实验室将继续探索更大规模模型的训练,以实现更广泛的语言覆盖和更卓越的性能。同时,我们也将优化模型以适应低延迟和实时应用场景,使其在更多领域发挥价值。此外,海天瑞声计划进一步加大对稀缺语言语种数据集的研发支持,为全球语音识别技术的均衡发展贡献力量。
Dolphin不仅是一款技术先进的语音识别模型,更是推动东方语言语音识别技术发展的重要力量。海天瑞声期待与全球研究者和开发者共同携手,开创语音识别技术的新篇章。
